Trong bài viết ở P1, mình đã chọn Prompt Engineering + RAG, và ở đây mình sẽ giải thích chi tiết hơn RAG (Retrieval-Augmented Generation) là gì.
Xem toàn series tại đây
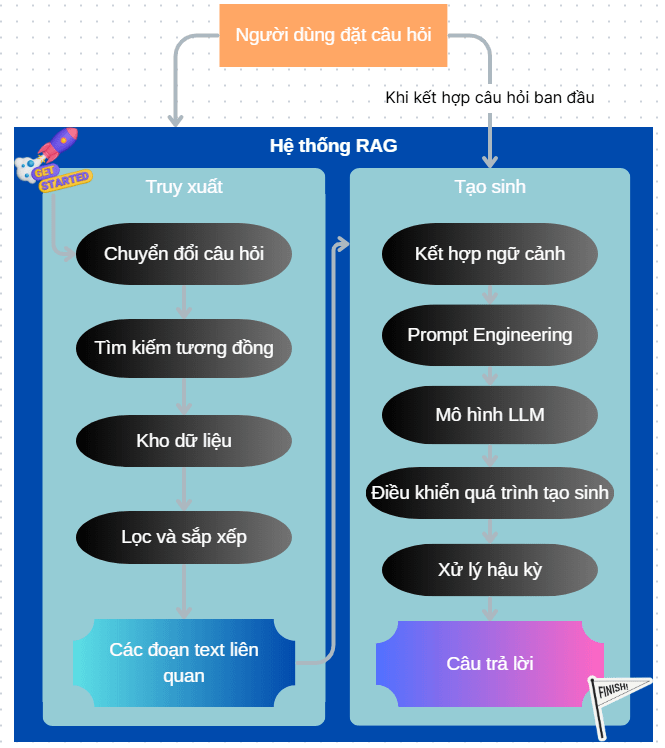
Giả sử người dùng đặt câu hỏi: “Ai là người đã viết ra cuốn sách ‘Sapiens’ và ông ấy nói gì về tương lai của loài người?”
Giai đoạn Truy xuất:
- Chuyển đổi câu hỏi (Query Encoding): Sử dụng các mô hình nhúng (embedding models) để chuyển đổi câu hỏi thành một vector số học nắm bắt ý nghĩa của nó.
- Ví dụ: Câu hỏi “Ai là người đã viết ra cuốn sách ‘Sapiens’ và ông ấy nói gì về tương lai của loài người?” sẽ được đưa qua một mô hình embedding để tạo ra một vector số, ví dụ: [-0.12, 0.55, 0.08, …, 0.92].
- Tìm kiếm tương đồng (Similarity Search): Sử dụng các kỹ thuật như cosine similarity để tìm kiếm các vector tài liệu gần nhất với vector câu hỏi trong không gian vector của Kho dữ liệu.
- Ví dụ: Vector của câu hỏi được so sánh với các vector của các mục trong kho dữ liệu (ví dụ: các trang sách, bài báo, tài liệu web đã được chia thành các đoạn và vector hóa). Các đoạn văn bản có vector “gần” nhất với vector câu hỏi sẽ được chọn. Ví dụ, có thể tìm thấy các đoạn văn bản sau:
- “Cuốn sách ‘Sapiens: Lược sử loài người’ được viết bởi Yuval Noah Harari.”
- “Trong ‘Sapiens’, Harari khám phá lịch sử tiến hóa của loài Homo sapiens từ thời kỳ đồ đá đến thế kỷ 21.”
- “Ở phần cuối của ‘Sapiens’, Harari suy đoán về tương lai của loài người, đặc biệt là sự trỗi dậy của công nghệ sinh học và trí tuệ nhân tạo, có khả năng định hình lại bản chất con người.”
- Ví dụ: Vector của câu hỏi được so sánh với các vector của các mục trong kho dữ liệu (ví dụ: các trang sách, bài báo, tài liệu web đã được chia thành các đoạn và vector hóa). Các đoạn văn bản có vector “gần” nhất với vector câu hỏi sẽ được chọn. Ví dụ, có thể tìm thấy các đoạn văn bản sau:
- Kho dữ liệu (Knowledge Base): Thường là một cơ sở dữ liệu vector (ví dụ: ChromaDB, Weaviate, FAISS) hoặc một kho lưu trữ tài liệu đã được xử lý và vector hóa. Trong giải pháp này, chúng ta đã đưa nó lên Google Cloud và vector hóa các tài liệu này. Kho dữ liệu này là Tĩnh. Ở phần kho dữ liệu này có một góc nhìn khác tùy theo nhu cầu, nếu nhu cầu của chúng ta là một kho dữ liệu được lấy, đào tạo và cập nhật tự động từ một nguồn nào đó bằng cách Cào Dữ Liệu (Web Scraping), chúng ta sẽ phải đi sâu vào giải pháp web scraping để tạo Knowledge base (mình dự định đưa vào Bài tiếp theo, hãy theo dõi thêm).
- Ví dụ: Kho dữ liệu có thể chứa toàn bộ nội dung của cuốn sách “Sapiens” đã được chia thành các đoạn văn bản và vector hóa, cùng với vector của nhiều sách và tài liệu khác.
- Lọc và sắp xếp (Filtering & Ranking): Có thể bao gồm các bước để lọc bớt các kết quả không liên quan và sắp xếp các kết quả theo mức độ liên quan.
- Ví dụ: Các đoạn văn bản được tìm thấy ở bước tìm kiếm tương đồng, có thể được sắp xếp dựa trên điểm số cosine similarity với vector câu hỏi. Chỉ một số lượng nhất định các đoạn có điểm số cao nhất sẽ được giữ lại để chuyển sang giai đoạn tạo sinh. (Điểm này chúng ta có thể cấu hình được khi gọi Vertex API)
- Lấy ra các văn bản liên quan: Đây là kết quả của giai đoạn truy xuất, bao gồm một hoặc nhiều đoạn văn bản được cho là có liên quan nhất đến câu hỏi của người dùng.
- Ví dụ: Các đoạn văn bản được chọn ở bước Lọc và sắp xếp (ví dụ: 2-3 đoạn có độ tương đồng cao nhất) sẽ được chuyển đến giai đoạn tạo sinh.
Giai đoạn tạo sinh:
- Kết hợp ngữ cảnh (Contextualization): Câu hỏi ban đầu của người dùng và các đoạn văn bản liên quan được kết hợp lại để tạo thành một ngữ cảnh đầu vào cho mô hình ngôn ngữ lớn (LLM). Thông thường, chúng được đưa vào một prompt theo một cấu trúc nhất định.
- Ví dụ: Một prompt có thể được tạo ra như sau:
“Hãy trả lời câu hỏi sau dựa trên thông tin được cung cấp trong các đoạn văn bản sau đây. Nếu thông tin không có trong các đoạn văn bản, hãy trả lời rằng bạn không biết. Câu hỏi: Ai là người đã viết ra cuốn sách ‘Sapiens’ và ông ấy nói gì về tương lai của loài người? Các đoạn văn bản liên quan: 1. Cuốn sách ‘Sapiens: Lược sử loài người’ được viết bởi Yuval Noah Harari. 2. Ở phần cuối của ‘Sapiens’, Harari suy đoán về tương lai của loài người, đặc biệt là sự trỗi dậy của công nghệ sinh học và trí tuệ nhân tạo, có khả năng định hình lại bản chất con người.”
- Ví dụ: Một prompt có thể được tạo ra như sau:
- Prompt Engineering: Bước này tập trung vào việc thiết kế và tinh chỉnh prompt để hướng dẫn LLM tạo ra câu trả lời chính xác, mạch lạc và phù hợp với yêu cầu. Các kỹ thuật prompt engineering có thể bao gồm: có vai trò và ngữ cảnh rõ ràng, chỉ định định dạng đầu ra mong muốn, có vài ví dụ, v.v. Phần sau mình sẽ viết thêm về nó, vì nó là linh hồn và sự khác biệt của bạn khi sử dụng đúng cách.
- Ví dụ: Thay vì prompt đơn giản ở trên, một prompt được thiết kế tốt hơn có thể là:
“Bạn là một trợ lý nghiên cứu uy tín trong lĩnh vực lịch sử và triết học. Hãy trả lời câu hỏi sau một cách chi tiết và có trích dẫn dựa trên các đoạn thông tin được cung cấp. Nếu thông tin không có trong các đoạn văn bản, hãy trả lời một cách trung thực rằng bạn không tìm thấy thông tin đó.
Vài ví dụ câu hỏi và cách bạn sẽ trả lời:
Dưới đây là ví dụ về cách bạn sẽ trả lời:
Câu hỏi: Napoleon Bonaparte sinh năm nào?
Đoạn văn bản: Napoleon Bonaparte sinh ra tại Ajaccio, Corsica vào ngày 15 tháng 8 năm 1769.
Trả lời: Napoleon Bonaparte sinh ra vào năm 1769 (theo đoạn văn bản cung cấp).
Dựa trên các đoạn thông tin sau, hãy trả lời câu hỏi một cách chi tiết. Trích dẫn nguồn nếu có thể. Câu hỏi: [Câu hỏi]
Các đoạn thông tin: [các đoạn văn bản liên quan]
Định dạng câu trả lời mong muốn:
Tác giả: [Tên tác giả]
Quan điểm về tương lai: [Tóm tắt quan điểm, có trích dẫn nếu phù hợp]
“
- Ví dụ: Thay vì prompt đơn giản ở trên, một prompt được thiết kế tốt hơn có thể là:
- Mô hình ngôn ngữ lớn (LLM): Ví dụ: Gemini, GPT-4, Llama 2, v.v. nhận prompt đã được chuẩn bị làm đầu vào và sử dụng kiến thức sẵn có của nó kết hợp với thông tin được cung cấp trong ngữ cảnh để tạo ra câu trả lời.
- Ví dụ: LLM sẽ xử lý prompt và tạo ra một câu trả lời dựa trên thông tin trong các đoạn văn bản, ví dụ: “Cuốn sách ‘Sapiens: Lược sử loài người’ được viết bởi Yuval Noah Harari. Trong cuốn sách, ở phần cuối, ông ấy suy đoán về tương lai của loài người, đặc biệt nhấn mạnh vào sự phát triển của công nghệ sinh học và trí tuệ nhân tạo, cho rằng chúng có tiềm năng thay đổi sâu sắc bản chất con người.”
- Điều khiển quá trình tạo sinh (Generation Control): Các kỹ thuật này được sử dụng để kiểm soát các khía cạnh của quá trình tạo sinh, chẳng hạn như độ dài của câu trả lời, mức độ sáng tạo, tránh lặp lại, hoặc đảm bảo tuân thủ các quy tắc nhất định. Các tham số decoding (ví dụ: temperature, top-k, top-p) cũng được điều chỉnh ở bước này
- Ví dụ: Có thể đặt giới hạn về độ dài của câu trả lời hoặc yêu cầu LLM tập trung vào các thông tin chính được cung cấp trong các đoạn văn bản. Hoặc điều chỉnh mức độ sáng tạo Temperature để tránh nó trả lời quá xa.
- Xử lý hậu kỳ (Post-processing): Có thể bao gồm việc loại bỏ thông tin thừa, định dạng lại văn bản, hoặc kiểm tra tính chính xác.
- Ví dụ: Câu trả lời có thể được định dạng lại dưới dạng một đoạn văn bản hoàn chỉnh, loại bỏ các câu dẫn không cần thiết hoặc thêm các trích dẫn nguồn rõ ràng nếu được yêu cầu. Hoặc tạo hình ảnh, video nếu có.
- Câu trả lời: Đây là đầu ra cuối cùng của hệ thống RAG, cung cấp câu trả lời cho câu hỏi ban đầu của người dùng dựa trên cả kiến thức của LLM và thông tin được truy xuất từ kho dữ liệu.
- Ví dụ: Tác giả: Yuval Noah Harari (theo Đoạn 1 cung cấp – đây là các link đến tài liệu).
- Quan điểm về tương lai: Dựa trên Đoạn 3, Yuval Noah Harari suy đoán về tương lai của loài người, đặc biệt tập trung vào sự trỗi dậy của công nghệ sinh học và trí tuệ nhân tạo. Ông cho rằng những tiến bộ này có khả năng “định hình lại bản chất con người” và dẫn đến “những thay đổi chưa từng có trong lịch sử loài người” (theo Đoạn 3).
Xem full series về tích hợp AI Assistant vào hệ thống chat box hiện tại, bằng cách sử dụng Google Vertex: Xem thêm tại đây.